


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Ina, Takuya; Idomura, Yasuhiro; Imamura, Toshiyuki*; Onodera, Naoyuki
Proceedings of International Conference on High Performance Computing in Asia-Pacific Region (HPC Asia 2023) (Internet), p.29 - 34, 2023/02
Mixed precision Krylov solvers with the Jacobi preconditioner often show significant convergence degradation when the Jacobi preconditioner is computed in low precision such as FP16 and BF16. It is found that this convergence degradation is attributed to loss of diagonal dominance due to roundoff errors in data conversion. To resolve this issue, we propose a new data conversion method, which is designed to keep diagonal dominance of the original matrix data. The proposed method is tested by computing the Poisson equation using the conjugate gradient method, the general minimum residual method, and the biconjugate gradient stabilized method with the FP16/BF16 Jacobi preconditioner on NVIDIA V100 GPUs. Here, the new data conversion is implemented by switching the round-nearest, round-up, round-down, and round-towards-zero intrinsics in CUDA, and is called once before the main iteration. Therefore, the cost of the new data conversion is negligible. When the coefficients of matrix is continuously changed by scaling the linear system, the conventional data conversion based on the round-nearest intrinsic shows periodic changes of the convergence property depending on the difference of the roundoff errors between diagonal and off-diagonal coefficients. Here, the period and magnitude of the convergence degradation depend on the bit length of significand. On the other hand, the proposed data conversion method is shown to fully avoid the convergence degradation, and robust mixed precision computing is enabled for the Jacobi preconditioner without extra overheads.
Idomura, Yasuhiro; Ina, Takuya*; Ali, Y.*; Imamura, Toshiyuki*
Dai-34-Kai Suchi Ryutai Rikigaku Shimpojiumu Koen Rombunshu (Internet), 6 Pages, 2020/12
A new communication avoiding (CA) Krylov solver with a FP16 (half precision) preconditioner is developed for a semi-implicit finite difference solver in the Gyrokinetic Toroidal 5D full-f Eulerian code GT5D. In the solver, the bottleneck of global collective communication is resolved using a CA-Krylov subspace method, and halo data communication is reduced by the FP16 preconditioner, which improves the convergence property. The FP16 preconditioner is designed based on the physics properties of the operator and is implemented using the new support for FP16 SIMD operations on A64FX. The solver is ported also on GPUs, and the performance of ITER size simulations with 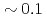 trillion grids is measured on Fugaku (A64FX) and Summit (V100). The new solver accelerates GT5D by
trillion grids is measured on Fugaku (A64FX) and Summit (V100). The new solver accelerates GT5D by 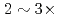 from the conventional non-CA solver, and excellent strong scaling is obtained up to 5,760 CPUs/GPUs both on Fugaku and Summit.
from the conventional non-CA solver, and excellent strong scaling is obtained up to 5,760 CPUs/GPUs both on Fugaku and Summit.
Idomura, Yasuhiro; Ina, Takuya*; Ali, Y.*; Imamura, Toshiyuki*
Proceedings of Joint International Conference on Supercomputing in Nuclear Applications + Monte Carlo 2020 (SNA + MC 2020), p.225 - 230, 2020/10
A new communication avoiding (CA) Krylov solver with a FP16 (half precision) preconditioner is developed for a semi-implicit finite difference solver in the Gyrokinetic Toroidal 5D full-f Eulerian code GT5D. In the solver, the bottleneck of global collective communication is resolved using a CA-Krylov subspace method, while the number of halo data communication is reduced by improving the convergence property using the FP16 preconditioner. The FP16 preconditioner is designed based on the physics properties of the operator and is implemented using the new support for FP16 SIMD operations on A64FX. The solver is ported on Fugaku (A64FX) and Summit (V100), which respectively show 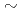 63x and 29x speedups in socket performance compared to the conventional non-CA Krylov solver on JAEA-ICEX (Haswell).
63x and 29x speedups in socket performance compared to the conventional non-CA Krylov solver on JAEA-ICEX (Haswell).
Idomura, Yasuhiro; Ina, Takuya*; Mayumi, Akie; Yamada, Susumu; Imamura, Toshiyuki*
Lecture Notes in Computer Science 10776, p.257 - 273, 2018/00
Times Cited Count:2 Percentile:50.01(Computer Science, Artificial Intelligence)A preconditioned Chebyshev basis communication-avoiding conjugate gradient method (P-CBCG) is applied to the pressure Poisson equation in a multiphase thermal-hydraulic CFD code JUPITER, and its computational performance and convergence properties are compared against a preconditioned conjugate gradient (P-CG) method and a preconditioned communication-avoiding conjugate gradient (P-CACG) method on the Oakforest-PACS, which consists of 8,208 KNLs. The P-CBCG method reduces the number of collective communications with keeping the robustness of convergence properties. Compared with the P-CACG method, an order of magnitude larger communication-avoiding steps are enabled by the improved robustness. It is shown that the P-CBCG method is 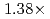 and
and 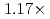 faster than the P-CG and P-CACG methods at 2,000 processors, respectively.
faster than the P-CG and P-CACG methods at 2,000 processors, respectively.
Mayumi, Akie; Idomura, Yasuhiro; Yamada, Susumu; Ina, Takuya; Yamashita, Susumu
no journal, ,
In this work, we implemented the Communication-Avoiding CG (CA-CG) method to the Poisson solver in the JUPITER code, which analyzes a multi-phase thermal-hydraulic problem, and evaluated its convergence property and computational performance. We analyzed the degradation of the convergence property due to accumulation of numerical errors associated with CA procedures, and applied quad-precision computation to a part of the CA-CG method to improve the convergence property.
Idomura, Yasuhiro
no journal, ,
A communication-avoiding generalized minimal residual (CA-GMRES) method is applied to the gyrokinetic toroidal five dimensional Eulerian code GT5D, and its performance is compared against the original code with a generalized conjugate residual (GCR) method on the Oakforest-PACS (KNL). The CA-GMRES method has less memory access and collective communications than the GCR method, and thus, is suitable for future Exa-scale architectures with limited memory and network bandwidths. It is shown that compared with the original GCR version, the CA-GMRES version is accelerated by 1.32x, and the cost of data reduction communication is reduced from ~13% to ~1% of the total cost at 1,280 nodes.
Idomura, Yasuhiro
no journal, ,
This talk reviews exascale computing technologies in fusion plasma simulations developed under the Post-K priority issue. Burning plasmas in ITER consists of multi-species ions, and their spatio-temporal scales are more than an order of magnitude larger than existing devices. Therefore, burning plasma simulations in ITER require exascale computing. To this end, we have developed novel computing technologies, which enables highly efficient computation on latest many core processors and reduces the inter-node communication, in the five dimensional fusion plasma turbulence code GT5D, and their performances were demonstrated on the Oakforest-PACS, which consists of 8,208 XeonPhi7250 (KNL) processors.
Idomura, Yasuhiro
no journal, ,
This talk reviews computing technologies developed for extreme scale nuclear CFD simulations on latest many core computing platforms. At JAEA, there are needs for extreme scale CFD simulations for analyzing critical issues such as melt relocation behavior of nuclear reactors at severe accidents and environmental dynamics of radioactive substances. Although the latest many core platforms offer promising solutions for such high computing needs, accelerated computation reveals severe bottlenecks of inter-node communication and data I/O. To resolve these issues, we have developed novel communication-avoiding matrix solvers and an In-Situ visualization system for the three dimensional multi-phase and multi-component thermal hydraulic core, JUPITER, and their performances were demonstrated in on the Oakforest-PACS, which consists of 8,208 XeonPhi7250 (KNL) processors.
Idomura, Yasuhiro; Ina, Takuya*; Mayumi, Akie; Yamada, Susumu; Matsumoto, Kazuya*; Asahi, Yuichi*; Imamura, Toshiyuki*
no journal, ,
We propose a modified communication-avoiding generalized minimal residual (CA-GMRES) method, which reduces both computation and memory access by 30% with keeping the same CA property as the original CA-GMRES method. These numerical properties, less communication and computation with higher arithmetic intensity, are promising features for future exascale machines with limited memory and network bandwidths. The modified CA-GMRES method is applied to a large scale non-symmetric matrix in an implicit solver of the gyrokinetic toroidal five dimensional Eulerian code GT5D, and its performance is estimated on the Oakforest-PACS (KNL). The numerical experiment shows that compared with the generalized conjugate residual method, computing kernels are accelerated by 1.5x, and the cost of data reduction communication is reduced from 12.5% to 1% of the total cost at 1,280 nodes.
Mayumi, Akie; Idomura, Yasuhiro; Ina, Takuya*; Yamada, Susumu; Imamura, Toshiyuki*
no journal, ,
To improve the convergence property of the communication avoiding conjugate gradient (CA-CG) method is needed for applying it to ill conditioned problems such as the pressure Poisson equation in the multiphase CFD code JUPITER. In the CA-CG method, one can avoid more communication by increasing the number of CA steps. However, this makes the CA-CG method less robust against numerical errors. To resolve this problem, we apply the Chebyshev basis CG (CBCG) method to JUPITER.
Imamura, Toshiyuki*; Idomura, Yasuhiro; Ina, Takuya*; Yamashita, Susumu; Onodera, Naoyuki; Ali, Y.*; Yamada, Susumu
no journal, ,
Towards exascale computing on the Post-K computer, a novel matrix solvers are developed by using communication avoiding algorithms. In this talk, we review two main approaches used in the three-dimensional thermal hydraulic multi-phase CFD code, JUPITER. One is a communication avoiding Krylov sub-space method, in which multiple basis vectors are generated and orthogonalized at once to reduce global collective communications. The other is a Krylov sub-space method with multi-grid preconditioning, which dramatically improve convergence property and reduce the number of iterations, and thus, global collective communications. We compare these approaches on the latest many core platform.
Ina, Takuya; Idomura, Yasuhiro; Imamura, Toshiyuki*; Yamashita, Susumu; Onodera, Naoyuki
no journal, ,
We have developed mixed-precision preprocessing for the preconditioned conjugate gradients (PCG) method in the multi-phase multi-component thermal-hydraulic code JUPITER. The preconditioner employs a hybrid mixed-precision approach which combines FP16 data and FP32 operations. The roundoff errors are reduced by converting FP16 data to FP32 on cache, holding the intermediate result in FP32, converting the final result to FP16, and returning it to the memory. The developed preconditioner was tested for large-scale problems with 3D structured grids of 3,200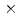 2,00014,160. The convergence of the PCG method was maintained even when the FP16 data format was used for ill-condition matrices, and the computational speed was dramatically increased by reducing the memory access. The hybrid FP16/32 mixed-precision implementation achieved 1.79 speedup from the FP64 implementation at 2,000 nodes on Fugaku.
2,00014,160. The convergence of the PCG method was maintained even when the FP16 data format was used for ill-condition matrices, and the computational speed was dramatically increased by reducing the memory access. The hybrid FP16/32 mixed-precision implementation achieved 1.79 speedup from the FP64 implementation at 2,000 nodes on Fugaku.
Idomura, Yasuhiro
no journal, ,
A gyrokinetic toroidal 5D Eulerien code GT5D resolves global torus plasma using 5D grids, and core plasma simulations of ITER require exascale computing on Fugaku. To this end, we developed a new communication avoiding (CA) Krylov solver with FP16 preconditioning for implicit finite difference computation, which occupies more than 80% of the total computing cost in GT5D. In this solver, a bottleneck of global collective communication is resolved using a CA Krylov subspace method. In addition, halo communication is reduced by improving the convergence property with FP16 preconditioning. The FP16 preconditioner was designed based on physics properties of the operator, and was implemented using FP16 SIMD operations. Compared with the conventional solver, the new solver improved the performance of ITER size simulations with ~100 billion grids by ~3.5x, and a good strong scaling was achieved up to 5,760 nodes.
Idomura, Yasuhiro
no journal, ,
Thanks to new technologies such as KNL and MCDRAM, Oakforest-PACS (OfP) achieved significantly high computing power and memory bandwidths against the conventional multi-core platforms, and played an important role as a prototype of exascale supercomputers. We developed extreme scale nuclear CFD simulations on OfP, where an important issue was to resolve communication bottlenecks revealed by accelerated computation. This issue was resolved by developing communication-avoiding (CA) matrix solvers based on CA Krylov subspace methods and CA multigrid methods, and high performance CFD simulations were enabled by using the full system size on OfP. In this talk, we review CA matrix solvers developed for the five dimensional plasma simulation code GT5D and the three dimensional multi-phase multi-component thermal-hydraulic code JUPITER.
Ina, Takuya; Idomura, Yasuhiro; Imamura, Toshiyuki*; Yamashita, Susumu; Onodera, Naoyuki
no journal, ,
The performance of low-precision computation is several times higher than that of double-precision computation on state-of-the-art supercomputers such as Fugaku and Summit, and mixed-precision processing utilizing FP16 and Bfloat16 is effective. However, the application of low-precision arithmetic to iterative solvers for ill-conditioned matrices in multiphase CFD simulations causes convergence deterioration. We developed a mixed-precision preconditioner for Krylov subspace methods for the multiphase thermal hydraulics code JUPITER, and both sustained convergence and improved performance were achieved by scaling matrices and by applying FP16/FP32 mixed-precision preprocessing on A64FX. In this study, we test the mixed-precision preprocessing using BFloat16, which is supported on NVIDIA GPUs. Bfloat16 has the same dynamic range as FP32 and does not require the scaling procedure, which is needed to prevent overflows in FP16 processing. As a result, we confirmed a 7% speedup in preconditioner by using Bfloat16 compared to the conventional one using FP16. However, in some cases, convergence was worse with Bfloat16, which has fewer bits in the mantissa than FP16.
Kato, Rino*; Hida, Takenori*; Tsutsumi, Hideaki*; Takada, Tsuyoshi
no journal, ,
With the aim of constructing a more realistic earthquake response analysis model of a nuclear facility, we constructed a model using the system identification method developed by the authors making maximum use of the strong motion observation records in the past earthquakes, and discussed its validity.
Ina, Takuya; Idomura, Yasuhiro; Imamura, Toshiyuki*
no journal, ,
State-of-the-art supercomputers are based on CPUs/GPUs with a wide variety of architectures, including Nvidia, AMD, and Intel. Each manufacturer provides its own programming environment for its architecture. Therefore, it is necessary to develop a code using different programming environments for each supercomputer. In addition, each architecture has a different hardware-support for floating-point number types. Therefore, there is a problem that when unsupported floating-number types are used, the calculation cannot be performed or the performance is degraded due to software emulation. DPC++, Intel's preferred programming model, is an implementation of a programming language called SYCL, which is a portable programming language standardized by the Khronos group and based on C++, allowing a single source code to run on multiple CPUs/GPUs. In addition, since there are multiple implementations of SYCL, performance improvement can be expected by selecting an implementation suitable for the architecture and the algorithms used. In addition, since Intel supports DPC++, efforts and information on SYCL will be widely available in the future. In this study, we evaluated the performance of the multiple-precision conjugate gradient solver using SYCL, with sparse matrix storage formats of Compressed Row Storage and Diagonal Storage for the 3-D Poisson equation.
